




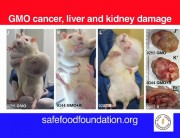
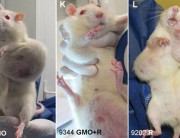
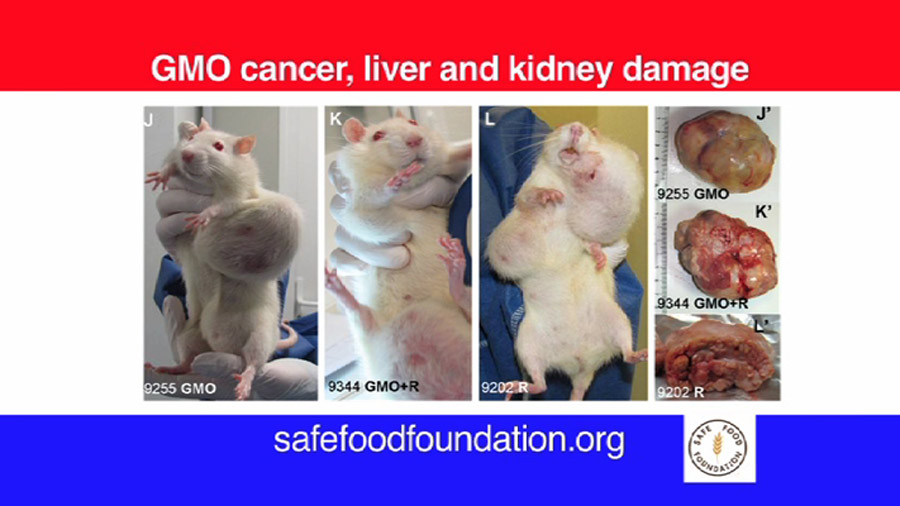
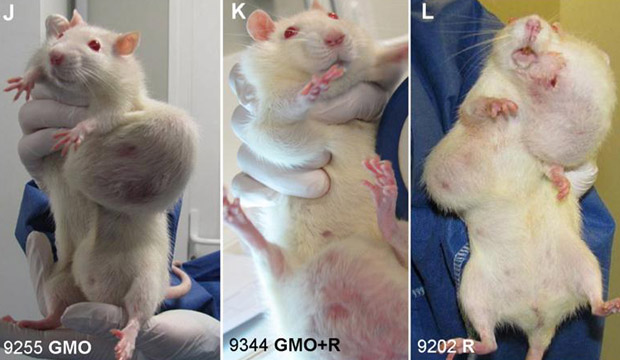
The study on the harmful impact of GMOs, carried out on the initiative of Professor Séralini and his team, has raised stormy reactions: many critics have questioned the validity of the research methodology. Paul Deheuvels, member of the Academy of Sciences and renowned statistician, explains why Séralini’s study is reliable.
Edited by Gaelle-Marie Zimmermann
Author sponsored by Guillaume Malaurie
The purpose of this forum is to provide my strongest support to G.E. Séralini, professor at the University of Caen. I learned that Professor Séralini had carried out some comparative studies, which have had a considerable impact.
To my knowledge, these surveys were designed and analyzed in accordance with the best professional standards, and should be appreciated as such.
The duration of the experiment: a pledge of reliability
One of the most interesting and innovative points of these experiments is that they were carried out over unusually long periods. It is a notorious fact known to experimenters that similar analyses conducted over shorter periods are not able to detect long-term toxic effects.
The particular case of tumour development falls into this category, and it is therefore not surprising that existing studies conducted over shorter periods than Séralini’s work have not thus far revealed significant differences in treatment groups [compared with controls].
So I think Professor Séralini provided very strong evidence sufficient to establish the existence of some unexpected toxic effects from products previously considered safe.
Of course, there will always be people who challenge these results, because of the fact that they are likely to have important consequences for industry.
Their point of view cannot be sustained in the light of new experimental results, since there is no doubt about the seriousness and reliability of the actual conclusions of Professor Séralini.
Unfounded criticisms of the statistics: concrete explanations
G.E. Séralini has been criticized, for example, for carrying out his study with groups of 10 experimental animals, while commonly 50 are used.
This criticism is unfounded. Indeed, in a statistical study, one can either try to demonstrate the safety of a product, or to highlight its harmfulness.
Take the example of a product suspected of being poisonous. If it is administered to 5 patients and there are 5 deaths, there is no need to go further in order to decide that it is toxic. If, on the other hand, the 5 patients survive, this does not mean that the product is safe, because the 5 patients are not necessarily representative of the entire population.
It is for this reason that studies sponsored by companies wishing to gain a verdict of safety for their products are required to use samples of a minimum stipulated size.
In this case, it is natural to insist on a minimum of 50 experimental animals (here, rats) for comparative analysis. But it is quite different if one is looking for for toxic effects. In this case, the fact that significant differences were detected in small groups (10 in the case study G.E. Seralini) reinforces the conclusion, instead of weakening it.
Two types of errors in statistical studies
I conclude by emphasizing the following principle: In a statistical study, if we detect toxic effects, there is always a risk of error, but the error, if any, can be easily dissipated by subsequent analyses. However, if studies find no effects, it is incorrect to deduce that these effects do not exist. Because there are two types of errors:
I. Detecting toxicity that does not in fact exist;
II. Claiming safety even though toxicity exists.
Most of the time, we control the risk of type I errors: the standard is to establish the decision-making rules so that the probability is set at 5%. In contrast, the risk of type II errors depends on the size of the study, and is often very high (40% or 60% or more).
It is in order to limit the risk of type II errors that studies involving many individual experiments (or experimental animals) are imposed. On the other hand, when toxicity is detected, there is only a 5% chance of error, regardless of the number of animals used.
Source: Le Nouvel Observateur (Translated by GM Watch)






















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}